
Marketing vs. Realität zur Datenanalyse am Beispiel (Sonder-)Maschinenbau
Kunde: »Ich hätte gerne drei Pfund Energieprognosen und etwas von der Kundenanalyse dabei.«
Anbieter: »Sehr gerne, darf es sonst noch etwas sein?«
Kunde: »Zudem noch ein Sechserpack hochqualitative Daten. Können Sie die bitte auf mein Unternehmen zuschneiden?«
So oder ähnlich mag es sich anfühlen, wenn man dem Medienwirbel um künstliche Intelligenz (KI) als Kernelement der aktuellen Digitalisierungsbewegung folgt. Ein vergleichbares Bild zeigt sich ebenfalls, wenn man die Angebote vieler Unternehmen betrachtet – beispielsweise auf Messebannern, Werbetafeln oder sogar in Leistungsangeboten. Wenn es also »KI von der Stange« gibt, wieso löst sie dann noch nicht fast alle unserer Probleme und wieso gibt es immer noch viele Unternehmen, die noch keine umfangreichen Einsatzgebiete erschlossen haben?
Was kann KI heute?
Schon im vergangenen Jahrhundert wurde durch Filme wie »Star Wars« und »Terminator« ein Bild von künstlicher Intelligenz geprägt, was menschenähnliche Fähigkeiten beinhaltet: Wahrnehmen und Verstehen der Umgebung sowie rationales und teilweise sogar emotionales Reagieren und Interagieren. Diese Art der KI wird auch als »Starke KI« bezeichnet. Was damals klar als Science-Fiction erkennbar war, verschwimmt in der öffentlichen Darstellung heute teilweise mit Anwendungen und Leistungsangeboten von Unternehmen. Tatsächlich sind heutige KI-Anwendungen aber nur in der Lage, sehr spezifische Probleme wie Unterscheiden, Gruppieren, Klassifizieren usw. zu lösen, was auch als »Schwache KI« bezeichnet wird. Was einfach klingt kann aber dennoch große Herausforderungen und auch entsprechende Mehrwerte bringen: das Klassifizieren eines Werkstücks als »makellos« oder »Ausschussteil« auf Basis von Bilddaten oder Erschütterungsprofilen einer Maschine bspw. hat das Potential, Kosten zu senken und die Qualität von Chargen zu erhöhen.
Viele Probleme und Verfahren sind schon gut erforscht und es gibt Best Practices dazu. Dennoch stellt sich immer wieder die Frage: Was steckt in den Daten? Nur weil ein Verfahren für Unternehmen A funktioniert, muss dasselbe Verfahren noch nicht für Unternehmen B funktionieren. Meistens liegt das daran, dass die Daten einfach anders sind oder aber (noch) nicht in hinreichender Qualität und Menge zur Verfügung stehen. Nicht umsonst heißt es, dass bei einem üblichen Datenprojekt mehr als die Hälfte der Aufwände in der Datenerlangung und -aufbereitung liegen.
Daten und deren Analyse in der Fertigung
Betrachtet man die Herausforderungen am zuvor genannten Beispiel der Ausschussteilerkennung, steht zuerst die Frage im Raum, an welchen Daten ein Ausschussteil erkannt werden kann. Wenngleich es hier Best Practices gibt, so unterscheidet sich die Produktion verschiedener Werkstücke erheblich. Was im einen Fall mit Energieverbrauch oder Erschütterung der Maschine gelöst werden kann, braucht in anderen Fällen wohlmöglich viele verschiedene Daten zusammen oder sogar Kameraaufnahmen für Bildauswertungen. Ein Maschinenbauer, der hunderte oder tausende Maschinen desselben Typs bei seinen Kunden hat, kann hier ggf. relativ zügig ein lohnendes Angebot für seinen Maschinentyp erstellen. Dennoch kann sich auch die Verwendung der Maschinen von Kunde zu Kunde unterscheiden. Verschiedene Konfigurationen haben ebenso Auswirkungen auf die Daten wie Umgebungseinflüsse. Temperatur und Luftfeuchtigkeit sind Beispiele für solche Einflüsse, die leicht zu Änderungen in den Daten führen können. Solche Varianzen in den Daten können dann Einflüsse auf den Erfolg der angewendeten KI-Verfahren haben. Die Herausforderungen werden also größer, je größer die Unterschiede im jeweiligen Anwendungsfall werden.
Meistens lohnt es sich, nicht den »großen KI-Anwendungsfall« direkt erreichen zu wollen, sondern mit eben diesem Anwendungsfall vor Augen ein kleinschrittiges Vorgehen zu planen, bei dem Mehrwerte unterwegs mitgenommen werden. Da das Sammeln und Aufbereiten von Daten lange Zeit in Anspruch nehmen kann, ist ein Return of Invest auf dem Weg zur KI-Lösung wichtig. Wird nicht nur ein kleiner Service geplant, sondern eine nachhaltige Datenstrategie angestrebt, so lohnt sich zudem das Aufbauen sauberer, unternehmensweiter Datenbasen, sei es durch gut verwaltete »klassische« Datenbanken, Data Warehouses oder Data Lakes. Das betont nochmal die Wichtigkeit der Mehrwerte unterwegs. Abbildung 1 zeigt verschiedene Stufen der Datenverarbeitung – schon die Auswertung vergangener Daten bringt oft wichtige Erkenntnisse die zur zielgerichteten Weiterentwicklung von Produkten, zur Verbesserung von Prozessen oder Erhöhung der Qualität führen können. Versetzt man sich in die Lage, auf Daten in Echtzeit reagieren zu können, schafft man die Möglichkeit, auf Probleme unverzüglich zu reagieren und Mitarbeiter stark zu entlasten. Oft ist es sinnvoll, solche Potentiale mit »klassischen« Methoden zu erschließen, ehe eine Umsetzung von Lösungen mit KI angestrebt wird.
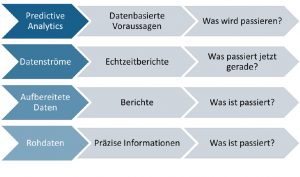
Abbildung 1: Datenverarbeitung in Stufen mit steigender Komplexität und damit Aufwand sowie Nutzen.
KI nicht zum Mitnehmen: ein Projekt im Kompetenzzentrum Stuttgart
Das Kompetenzzentrum Stuttgart bestreitet den Weg über die zuvor genannten Stufen der Datenverarbeitung in einem Projekt, gemeinsam mit Partnern aus dem Sondermaschinenbau sowie der Cloud-basierten Datenverwaltung. In diesem Kontext baute die Wichelhaus GmbH & Co. KG Maschinenfabrik eine flexible Industriemaschine auf, welche nicht nur in der Lage ist, umfangreiche Daten zu generieren, sondern auch gezielt Fehlverhalten wie Druckluftverlust zu erzeugen. Somit können KI-Verfahren gezielt darauf trainiert werden, auch mit Fehlverhalten umgehen zu können. Ältere Maschinen können durch Retrofitting ebenfalls Daten erzeugen, hierfür kann bspw. die ConnectBox der Rhein-Nadel Automation GmbH genutzt werden. Um die Daten flexibel aus einer strukturierten Quelle zentral bereitzustellen, bringt die bimanu Cloud Solutions GmbH ein Cloud-basiertes Data Warehouse ein. Das Kompetenzzentrum unterstützt insbesondere zu den Datenkonzepten sowie der Auswahl und Konfiguration von KI-Verfahren.
Mehr Details zum Projekt gibt es im bimanu-Blog bei der Projektvorstellung: Machine Learning Projekt mit dem Fraunhofer IAO im Mittelstand 4.0-Kompetenzzentrum Stuttgart!








